GPT-4.1, mini, nano 총정리: 성능, 가격, 활용법까지 한번에
GPT-4.1 시리즈의 혁신적 기능과 성능 향상을 소개합니다. 코딩, 긴 컨텍스트 처리, 지시 이행 능력이 크게 개선되었고, 최초의 나노 모델까지 출시된 GPT-4.1의 모든 것을 파헤쳐볼게요!

어제 정말 신기한 뉴스를 봤어요. OpenAI가 또 새로운 모델을 출시했더라고요. 요새 AI 기술이 진짜 미친 속도로 발전하는데, 그냥 따라가기도 버거울 지경이에요. 근데 이번에 나온 GPT-4.1 시리즈는 뭔가 특별해 보이더라고요. 코딩 능력이 확 좋아졌다는데, 개발자분들은 어떻게 생각하세요? 저같은 일반인한테도 도움될까요?
GPT-4.1 시리즈, 무엇이 달라졌을까? 🚀
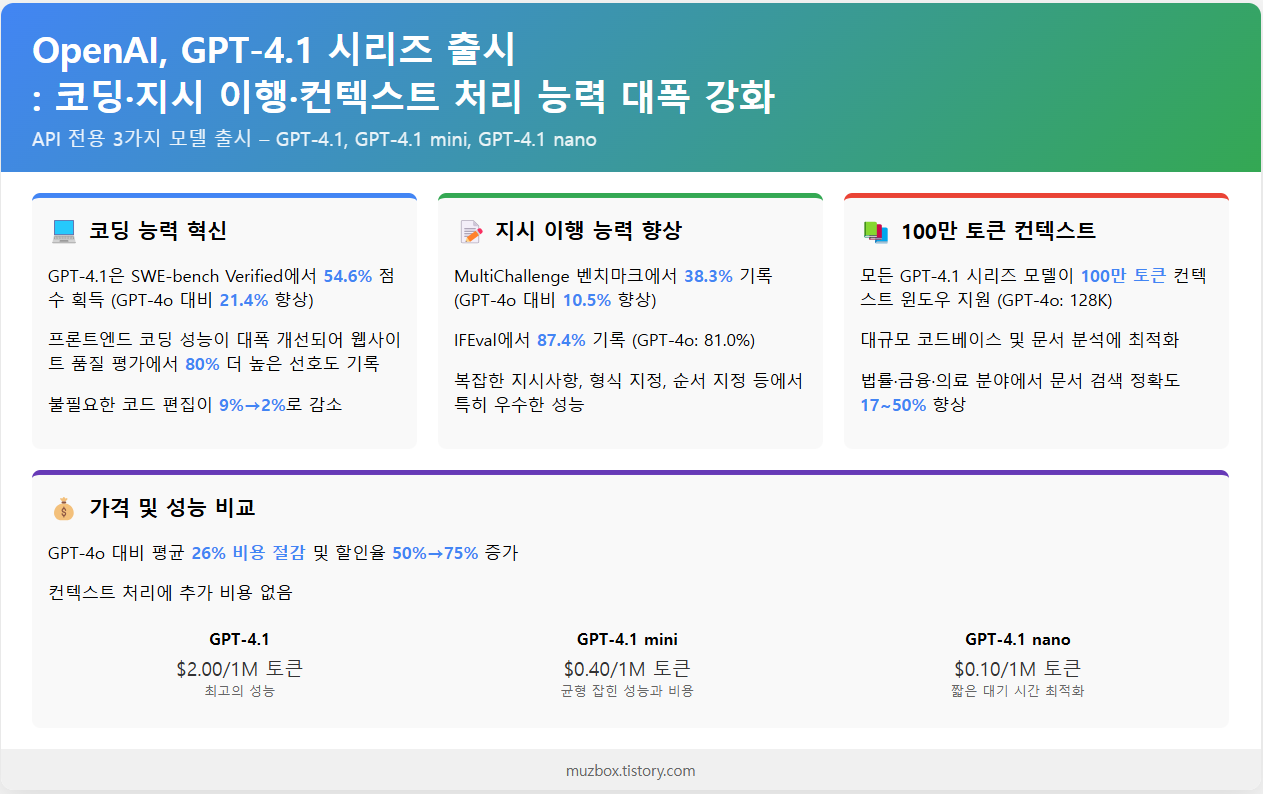
OpenAI가 API를 통해 제공하는 세 가지 새로운 모델을 소개했어요. GPT-4.1, GPT-4.1 mini, 그리고 GPT-4.1 nano까지. 이 모델들은 기존의 GPT-4o와 GPT-4o mini보다 전반적으로 더 뛰어난 성능을 보여준다고 해요. 특히 코딩과 지시사항 이행 능력에서 엄청난 발전이 있었다고 하네요.
가장 눈에 띄는 변화는 컨텍스트 윈도우의 크기예요. 무려 100만 토큰까지 처리할 수 있게 되었다고 해요! 이전 모델들이 128,000 토큰까지 처리할 수 있었던 것과 비교하면 정말 큰 발전이죠. 그리고 단순히 더 많은 컨텍스트를 처리하는 것뿐만 아니라, 그 컨텍스트를 더 효율적으로 이해하고 활용할 수 있게 되었다고 해요.
또한 지식 기반도 업데이트되어 2024년 6월까지의 정보를 담고 있어요. 이제 좀 더 최신 정보에 대해서도 물어볼 수 있겠네요.
코딩 능력이 대폭 향상됐어요 💻
제가 개인적으로 가장 흥미로웠던 부분은 코딩 능력의 향상이에요. GPT-4.1은 SWE-bench Verified에서 54.6%의 점수를 받았다고 해요. 이는 GPT-4o의 33.2%보다 무려 21.4% 포인트나 높은 점수예요!
| 모델 | SWE-bench Verified 점수 | 향상된 정도 |
|---|---|---|
| GPT-4.1 | 54.6% | 기준 |
| GPT-4o | 33.2% | -21.4% |
| GPT-4.5 | 38.0% | -16.6% |
실제 사용자들의 반응도 놀라웠어요. Windsurf라는 회사에서는 GPT-4.1이 내부 코딩 벤치마크에서 GPT-4o보다 60% 높은 점수를 받았다고 해요. 특히 도구 호출에서 30% 더 효율적이었고, 불필요한 편집을 반복할 가능성이 약 50% 낮았다고 하네요.
이거 진짜 대단한 발전 아닌가요? 개발자들이 코드를 작성하고, 디버깅하는 데 훨씬 더 도움이 될 것 같아요. 제가 개발자는 아니지만, 이런 발전이 미래의 소프트웨어 개발에 어떤 영향을 미칠지 정말 궁금해요.
지시 이행 능력도 확실히 좋아졌어요 📝
GPT-4.1은 지시 이행 능력도 크게 향상되었어요. 특히 Format following, Negative instructions, Ordered instructions, Content requirements, Ranking, Overconfidence 등 여러 범주에서 성능이 향상되었다고 해요.
| 벤치마크 | GPT-4.1 | GPT-4o | 향상도 |
|---|---|---|---|
| MultiChallenge | 38.3% | 27.8% | +10.5% |
| IFEval | 87.4% | 81.0% | +6.4% |
| 내부 API 지시 이행 (어려운 유형) | 49.1% | 29.2% | +19.9% |
실제로 세금 관련 회사인 Blue J에서는 GPT-4.1이 내부 벤치마크에서 GPT-4o보다 53% 더 정확했다고 해요. Hex라는 회사에서는 SQL 평가 세트에서 거의 2배 향상된 성능을 보였다고 하네요.
이런 개선은 복잡한 지시사항을 더 잘 따를 수 있게 해준다는 뜻이니까, 실무에서 활용도가 훨씬 높아질 것 같아요. 솔직히 말해서, 이전 모델들도 간단한 지시는 잘 따랐지만 복잡한 지시나 여러 단계의 지시는 종종 헷갈려 했잖아요? 이제 그런 문제가 많이 해결될 것 같네요.
100만 토큰의 긴 컨텍스트, 어떻게 활용할까? 📚
GPT-4.1 시리즈의 가장 큰 변화 중 하나는 100만 토큰의 컨텍스트 윈도우예요. 이건 React 코드베이스 전체를 8개 넣을 수 있는 양이라고 하네요. 진짜 엄청난 양이죠?
OpenAI는 GPT-4.1이 이 긴 컨텍스트에서 정보를 효과적으로 찾고 활용할 수 있도록 특별히 훈련시켰다고 해요. 'Needle in a Haystack' 테스트에서 GPT-4.1은 100만 토큰 안에 숨겨진 정보를 정확하게 찾아낼 수 있었다고 해요.
또 흥미로운 점은 OpenAI가 새로운 평가 방식인 OpenAI-MRCR과 Graphwalks를 공개했다는 거예요. 이 평가들은 모델이 긴 컨텍스트에서 여러 정보를 어떻게 찾고 연결하는지 테스트하는 방식이라고 해요.
| 모델 | 컨텍스트 윈도우 | OpenAI-MRCR (2 바늘) 128k | Graphwalks bfs <128k |
|---|---|---|---|
| GPT-4.1 | 100만 토큰 | 57.2% | 61.7% |
| GPT-4.1 mini | 100만 토큰 | 47.2% | 61.7% |
| GPT-4.1 nano | 100만 토큰 | 36.6% | 25.0% |
| GPT-4o | 128k 토큰 | 31.9% | 41.7% |
실제 사용 사례도 인상적이었어요. Thomson Reuters는 GPT-4.1을 사용해 다중 문서 검토 정확도를 17% 향상시켰고, Carlyle은 매우 큰 문서에서 세부적인 재무 데이터를 추출하는 성능이 50% 향상되었다고 해요.
솔직히 말해서, 이런 긴 컨텍스트 기능은 법률, 금융, 의료 등 복잡한 문서를 다루는 분야에서 정말 혁신적인 변화를 가져올 것 같아요. 생각해보세요, 수백 페이지의 계약서나 의료 기록을 한 번에 분석할 수 있다면 얼마나 편리할까요?
컨텍스트는 AI 모델이 대화나 질문을 이해하기 위해 고려하는 배경 정보나 이전 대화 내용을 의미해요. 쉽게 설명하자면, 사람과 대화할 때 이전에 나눈 모든 대화를 기억하고 참고하는 것과 비슷해요.
비전(Vision) 능력도 강화됐어요 👁️
GPT-4.1 시리즈는 이미지 이해 능력도 크게 향상되었어요. 특히 GPT-4.1 mini는 이미지 벤치마크에서 종종 GPT-4o보다 더 좋은 성능을 보여줬다고 해요.
| 벤치마크 | GPT-4.1 | GPT-4.1 mini | GPT-4o |
|---|---|---|---|
| MMMU | 74.8% | 72.7% | 68.7% |
| MathVista | 72.2% | 73.1% | 61.4% |
| CharXiv-R | 56.7% | 56.8% | 52.7% |
| Video-MME (자막 없음) | 72.0% | - | 65.3% |
MMMU에서 GPT-4.1은 74.8%, GPT-4.1 mini는 72.7%의 점수를 받았어요. 이는 GPT-4o의 68.7%보다 훨씬 높은 점수죠. MathVista에서도 GPT-4.1은 72.2%, GPT-4.1 mini는 73.1%로 GPT-4o의 61.4%를 크게 앞섰어요.
Video-MME 테스트에서는 GPT-4.1이 72.0%의 점수를 얻어 GPT-4o의 65.3%보다 훨씬 좋은 성적을 거뒀어요. 이 테스트는 30-60분 길이의 자막 없는 비디오를 기반으로 질문에 답하는 테스트인데, 정말 인상적인 성능이죠?
아직 사진이나 비디오를 많이 활용하진 않지만, 앞으로는 이런 비전 능력을 활용한 애플리케이션이 더 많아질 것 같아요. 제 생각엔 교육이나 의료 분야에서 특히 유용할 것 같네요.
가격은 어떻게 변했을까? 💰
가격도 상당히 흥미로웠어요. OpenAI는 추론 시스템의 효율성 향상으로 GPT-4.1 시리즈의 가격을 낮출 수 있었다고 해요.
| 모델 | 입력 (100만 토큰) | 캐시된 입력 (100만 토큰) | 출력 (100만 토큰) | 혼합 가격* |
|---|---|---|---|---|
| GPT-4.1 | $2.00 | $0.50 | $8.00 | $1.84 |
| GPT-4.1 mini | $0.40 | $0.10 | $1.60 | $0.42 |
| GPT-4.1 nano | $0.10 | $0.025 | $0.40 | $0.12 |
*일반적인 입력/출력 및 캐시 비율 기준
GPT-4.1은 중간 규모 쿼리의 경우 GPT-4o보다 26% 저렴하고, GPT-4.1 nano는 가장 저렴하고 빠른 모델이라고 해요.
또 하나 좋은 점은 캐시된 입력에 대한 할인이 이전의 50%에서 75%로 증가했다는 거예요. 같은 컨텍스트를 반복해서 전달하는 경우에 더 많은 비용을 절약할 수 있게 된 거죠.
확실히 더 저렴해진 가격은 중소기업이나 개인 개발자들에게 큰 도움이 될 것 같아요. 특히 GPT-4.1 nano는 정말 매력적인 가격대라고 생각해요.
내가 받은 느낌은? 🤔
이번 GPT-4.1 시리즈 발표를 보면서 정말 많은 생각이 들었어요. AI 기술이 이렇게 빠르게 발전하는 걸 보니 약간 두렵기도 하지만, 동시에 정말 기대되기도 해요.
특히 코딩 능력의 향상은 소프트웨어 개발 방식을 완전히 바꿀 수 있을 것 같아요. 개발자들이 복잡한 코드를 더 쉽게 작성하고 수정할 수 있게 되면, 더 빠르게 혁신적인 제품들이 나올 수 있겠죠.
긴 컨텍스트 기능도 정말 흥미로워요. 법률 문서, 의학 연구, 학술 논문 등 긴 문서를 분석하는 데 엄청난 도움이 될 것 같아요. 이전에는 불가능했던 방식으로 정보를 처리하고 통찰력을 얻을 수 있게 될 거예요.
지시 이행 능력의 향상은 AI가 더 신뢰할 수 있는 도구가 되었다는 걸 의미해요. 사용자가 원하는 정확한 결과를 더 쉽게 얻을 수 있게 되었으니까요.
하지만 여전히 몇 가지 질문도 남아있어요. 이런 강력한 AI 도구들이 사회에 어떤 영향을 미칠까요? 직업 시장은 어떻게 변할까요? 우리는 어떻게 이 기술을 책임감 있게 사용할 수 있을까요?
GPT-4.1 시리즈, 누구를 위한 모델일까? 🌍
GPT-4.1 시리즈는 다양한 사용자와 사용 사례를 위해 설계되었어요.
| 모델 | 주요 사용자층 | 주요 특징 | 비용 효율성 |
|---|---|---|---|
| GPT-4.1 | 최고 성능을 원하는 사용자 | 코딩 능력, 정확한 지시 이행, 긴 문서 분석 | 중간 |
| GPT-4.1 mini | 균형 잡힌 성능과 비용을 원하는 사용자 | GPT-4o보다 더 좋은 성능, 지연 시간 절반 | 높음 |
| GPT-4.1 nano | 짧은 대기 시간이 중요한 작업 | 분류, 자동 완성, 100만 토큰 컨텍스트 | 매우 높음 |
GPT-4.1은 최고의 성능을 원하는 사용자를 위한 모델이에요. 복잡한 코딩 작업, 정확한 지시 이행이 필요한 작업, 긴 문서 분석 등에 적합해요.
GPT-4.1 mini는 균형 잡힌 성능과 비용을 원하는 사용자에게 적합해요. GPT-4o보다 여러 벤치마크에서 더 좋은 성능을 보이면서도 지연 시간은 절반으로 줄고 비용은 83% 감소했다고 하니 정말 매력적이죠.
GPT-4.1 nano는 짧은 대기 시간이 중요한 작업에 적합해요. 분류나 자동 완성과 같은 작업에 이상적이라고 해요. 100만 토큰의 컨텍스트 윈도우를 가지고 있으면서도 MMLU에서 80.1%, GPQA에서 50.3%의 높은 점수를 받았대요.
저는 개인적으로 GPT-4.1 mini가 가성비 면에서 가장 좋은 선택일 것 같다는 생각이 들어요. 대부분의 일반적인 작업에 충분한 성능을 제공하면서도 비용은 상당히 저렴하니까요.
자주 묻는 질문 (FAQ) ❓
Q: GPT-4.1은 ChatGPT에서도 사용할 수 있나요?
A: 아니요, GPT-4.1은 API를 통해서만 제공됩니다. ChatGPT에서는 지시 이행, 코딩, 지능 향상 등의 개선 사항이 GPT-4o의 최신 버전에 점진적으로 통합되고 있습니다.
Q: GPT-4.1의 컨텍스트 윈도우는 얼마나 큰가요?
A: GPT-4.1, GPT-4.1 mini, GPT-4.1 nano 모두 100만 토큰의 컨텍스트 윈도우를 지원합니다.
Q: GPT-4.1 시리즈의 가격은 어떻게 되나요?
A: GPT-4.1은 입력 100만 토큰당 $2, GPT-4.1 mini는 $0.40, GPT-4.1 nano는 $0.10입니다. 출력 토큰은 각각 $8, $1.60, $0.40입니다.
Q: GPT-4.5 Preview는 어떻게 되나요?
A: GPT-4.5 Preview는 3개월 후인 2025년 7월 14일에 API에서 중단될 예정입니다. GPT-4.1이 더 낮은 비용과 지연 시간으로 더 좋거나 유사한 성능을 제공하기 때문입니다.
Q: GPT-4.1 시리즈의 지식 기반은 언제까지의 정보를 포함하고 있나요?
A: 2024년 6월까지의 정보를 담고 있습니다.